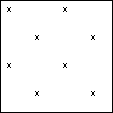fig. 1 - Échantillon élémentaire ou aléatoire simple
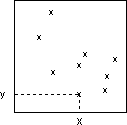
- Répartition des 9 points par tirage au sort des coordonnées x et y
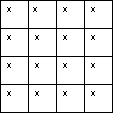
fig. 2 - Échantillon systématique (aligné)
V.1.71 - Dernière mise à jour : 11/11/2010
Sondage* : méthode expérimentale pour recueillir des informations sur une fraction réduite de la population. L'objectif est ensuite de généraliser à l'ensemble de la population ce qui a été trouvé sur la fraction.
Le sondage n'est pas apparu aussi vite que le recensement
car il nécessite certaines découvertes scientifiques et techniques
Des techniques issues de l'expérimentation
- Technique de l'échantillonnage
- sous produit de la théorie des probabilités
- remonte au XVIIe siècle
Problème de jeux de dés entre PASCAL et le Chevalier de MERE
- Technique du questionnaire
- enquête sociale au XVIII en Angleterre
- évaluation du budget des familles ouvrières
- Techniques du sondage d'opinion
- en 1936, GALLUP prévoit la victoire de ROOSEVELT sur LANDON
- GALLUP utilise un échantillon de 5 000 personnes prises au hasard
- Le Litterary Digest utilise un échantillon de 2 millions d'abonnés au téléphone
- Qui a donné le bon résultat ?
- en France, c'est en 1965 que l'IFOP (créé en 1935) pronostique un ballottage inattendu de de GAULLE au 1er tour des présidentielles.
Le sondage complète souvent les recensements
Il se fait plus souvent et à moindre coût
- C'est le cas du Recensement Général de l'Agriculture (RGA 2000)
entrecoupé de sondages TERUTI et de l'Inventaire Forestier National, par exemple.
Ces sondages doivent :
- améliorer la connaissance de certains postes d'occupation du sol ;
- augmenter la fréquence de mise-à-jour (TERUTI)
- C'est également le cas du Recensement général de la Population (RGP 1999) de l'INSEE et maintenant de celui du recensement rénové (RRP)
Entre les recensements, il y a des enquêtes sur :
- les conditions de vie des ménages
- la situation professionnelle et sociale
- etc.
Parfois, il est impossible d'étudier toute la population
- elle est trop nombreuse
ou
- d'effectif inconnu
Donc on étudie 1 sous ensemble : l'échantillon*
Échantillon => même caractéristiques que la population
- Un échantillon est représentatif* quand :
tout individu de la population mère peut figurer avec 1 probabilité connue dans l'échantillon
- A chaque échantillon est associé un risque d'erreur
Si le tirage suit une loi de probabilité connue
le risque d'erreur aléatoire est connu
L'erreur aléatoire est parfois moindre que la somme des erreurs d'un dénombrement exhaustif
Il existe 2 types d'erreurs dans les données d'enquête :
- les erreurs de mesure ;
- l'erreur aléatoire.
Elles peuvent être :
- accidentelles
=> mauvaises coches sur le questionnaire
=> mauvais enquêteurs (rédaction au bistro !)
- systématiques => questions mal rédigées donc mal comprises
Parmi les erreurs de mesures, il y a :
- Les erreurs d'observation et de transcription qui sont :
- présentes dans toutes les enquêtes
- Les erreurs de collectes, de codification, de saisie
se compensent tant qu'elles sont accidentelles
- Les erreurs ou biais systématiques
Tendent à se cumuler
- On ne voit que des gens chez eux aux heures ouvrables
=> chômeurs ou non actifs
=> gardiens d'immeuble
- Réponses non sincères
=> crainte de l'investigation
=> désir d'impressionner
=> questions délicates posées trop franchement (religion, sexe...)
=> voire fraudes (subventions)
En théorie, toute erreur systématique est dépistable
à cause de son systématisme
Elle est donc redressable
L'erreur aléatoire* => erreur due à l'échantillonnage
Elle est fonction de la taille de l'échantillon
- Elle n'est présente que dans les données issues d'un sondage
Car les paramètres sont déterminés non pas sur toute la population,
mais sur une sous partie représentative
- Si le tirage de l'échantillon est aléatoire
la marge d'incertitude se calcule
- La marge d'erreur diminue avec l'augmentation la taille de l'échantillon
- Les sondages cumulent :
- les erreurs de mesures ;
- les erreurs aléatoires.
- Lorsqu'une enquête échoue c'est plus fréquemment du fait :
- des erreurs de mesures ;
que
- des erreurs aléatoires.
Les erreurs de mesures ont plus de poids dans un sondage, car le nombre d'observations est plus faible que dans un recensement.
- Elles peuvent fausser les résultats
car elles sont souvent le fait de répondants à profil particulier
Les deux extrémités de l'échelle sociale sont les plus difficiles à joindre (pour des raisons différentes)
- Pour corriger, il faut :
- relancer ou re-tirer au hasard un répondant de même profil (!!!!) ;
- effectuer un redressement
On redresse par rapport à une distribution connue, comme :
- les constantes biologiques
Exemple :
- de la sur-mortalité féminine en Chine chez les 0-5 ans (ou des sous déclarations !)
En général, il naît 105 garçons pour 100 filles
En Chine en 2000, il naissait 117 garçons pour 100 filles (Libération du 18-19 IX 2004) contre 115 en 1997 (Le Monde 24 IX 1997).
Ce taux peut atteindre 130 garçons pour 100 filles dans certains secteurs indiens ou chinois.
- de la sur-représentation des garçons sur les filles selon le rang de naissance
En Corée du Sud en 1990, il y avait :
- 117 garçons pour 100 filles à la deuxième naissance ;
- 190 garçons pour 100 filles à la troisième naissance.
- Le redressement n'est possible que si les non-réponses sont faibles
- La base de sondage est une liste
- La base de sondage est une surface (carte, photo aérienne, image satellitale, ...)
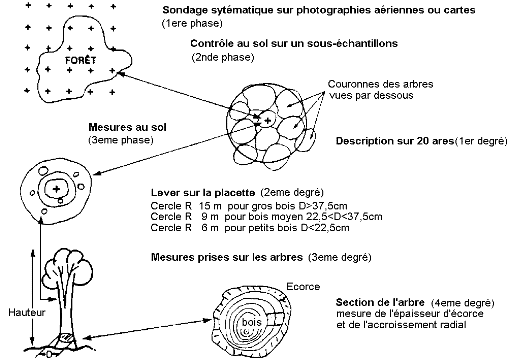
tab. 1 - Exemple d'échantillons
Individus Population Exemple d'échantillon Électeurs Population française en âge de voter 1 000 électeurs Exploitations agricoles Exploitations agricoles recensée dans le RGA 10 000 exploitations Parcelles élémentaires de territoires Surface agricole cultivée 6 000 parcelles élémentaires désignées par des points sur des photos
En travaux !!!
La plupart des enquêtes socio-démographiques reposent sur ce mode de sondage.
Système de 3 enquêtes emboîtées pour suivre l'évolution :
- de l'emploi ;
- du secteur informel ;
- de la pauvreté
dans les pays en voie de développement.
Enquêtes réalisées sur des capitales depuis une quinzaine d'année
- Phase 1 enquête emploi
- actualisation des bases de sondage existantes
- tirage à deux degrés (pour être précis : enquêtes aréolaires stratifiées à deux degrés)
- 1er degré : échantillonnage des Unités Primaires (UP) => des quartiers par exemple (unités aréolaires*)
- 2ème degré : échantillonnage des Unités Secondaires (US) => des ménages par exemple
ex. : Dans chaque capitale économique des 7 pays de l'UOMEA (CI, Mali, Bénin, Sénégal, Togo, Niger et BF), 125 UP ont été tirées, les ménages dénombrés, puis 20 US (ménages) ont été tirés par UP.
- questions relatives à l'emploi, au chômage et aux conditions d'activité des ménages
=> instrument de suivi du marché de l'emploi
=> sert de filtre pour tirer des Unités de Productions Informelles (UPI)
- Phase 2 enquête sur le secteur informel
Enquête sur les chefs d'UPI (condition d'activité, performances économiques, ...)
- tirage à probabilités inégales stratifié (sur la branche d'activité et le statut du chef d'unité de production)
- tirage aléatoire systématique dans chaque strate ;
- probabilité de tirage déterminée en fonction de l'importance numérique des statuts (les pas nombreux comme ceux ayant le statut de "patrons" sont tous enquêtés).
- Phase 3 enquête sur la consommation, les lieux d'achat et la pauvreté
Enquête sur la consommation des ménages (niveau de vie, poids des secteurs informels et formels dans la consommation, ...)
- stratification (issue de la phase 1) sur le revenu et la situation du chef de ménage.
Exemple d'enquête lourde dont il faut avoir connaissance pour se positionner quand on est seul avec son sujet de maîtrise.
cf. STATECO n°99, 2005, n° spécial de 195 pages sur l'enquête 1-2-3, publié par l'INSEE, AFRISTAT et DIAL
En travaux !!!
- Sondages spatiaux sans stratification géométrique (géographique)
fig. 1 - Échantillon élémentaire ou aléatoire simple
- Répartition des 9 points par tirage au sort des coordonnées x et y
fig. 2 - Échantillon systématique (aligné)
- Sondages spatiaux avec stratification géométrique (géographique)
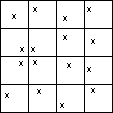
fig. 3 - Échantillon stratifié systématique aligné
fig. 4 - Échantillon stratifié systématique non aligné
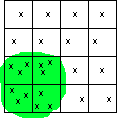
fig. 5 - Échantillon par grappe à deux degrés
- Sondages spatiaux avec stratification thématique (et géométrique)
fig. 6 - Échantillon stratifié avec probabilité inégale de tirage
fig. 7 - Exemple d'échantillon à quatre degrés
Sources : Inventaire Forestier National
Deux méthodes couramment utilisées :
(cf. DESABIE 1966, p. 44)
- le sondage par choix raisonné (unités types et quotas)
- le sondage par la méthode des itinéraires
Le principe : Construction d'un échantillon qui ressemble à la population dont il est issu
- Il se veut donc représentatif* (au sens courant du mot)
- La désignation de l'échantillon est raisonnée
- Consiste à diviser la population en un certain nombre de sous ensembles relativement homogènes
chaque sous ensemble est représenté par une unité-type
Exemple historique : les cantons-type tirés dans chaque petites régions agricoles (INSEE 1942)
- coût de collecte réduit de 5 à 1 ;
- risque de forcer le trait
C-à-D => prendre le plus typique !!! (le canton le plus viticole de la petite région agricole viticole)
- Inconvénient :
- comporte une part d'arbitraire que rien ne peut éliminer
- Avantage :
- permet d'extrapoler à partir d'un échantillon de très faible effectif
- Les caractères à observer n'étant pas, en général, indépendants entre eux ;
un échantillon qui ressemble à la population pour un caractère "important"
lui ressemble également pour un caractère lié au premier
- Le principe :
- On subdivise la population en classes
- les statistiques font connaître l'effectif de chacune d'elles
- cet effectif est multiplié par le taux de sondage* choisi
=> le résultat est le quota* à enquêter
- La méthode implique une bonne connaissance des statistiques de la population étudiée
- Choix des variables de contrôle :
- Pour être retenue comme variable de contrôle, il faut simultanément :
- avoir une distribution statistique connue ;
- être facile d'observation ;
- être fortement corrélée avec la ou les variables étudiées
Les deux premières conditions rendent possible l'application de la méthode
La dernière assure son efficacité
- Le choix des variables de contrôle est extrêmement limité
- La variable sexe répond-elle à ces critères ?
- La variable revenu répond-elle à ces critères ?
- Exemple :
Répartition de la population pour les variables de contrôle :
tab. 2 - sexe
Hommes Femmes Total 123 127 250 tab. 3 - âge
18-34 35-49 50-64 65 et + Total 119 80 33 18 250 tab. 4 - CSP
Artisans Petits com. Gros com. Prof. lib. Cadres sup. Cadres moy. Employés Ouvriers Inactifs Retraités Étudiants Total 13 18 98 102 19 250
- Les différentes variable de contrôle, utilisées simultanément, sont le plus indépendantes possible :
=> décorrélées*
Dans les sondages aléatoires, ces variables de contrôle sont utilisées pour définir les strates
- Contrôle marginaux et croisés :
- Quotas marginaux (ou indépendants)
Établis par contrôle séparé de la distribution des variables de contrôle
Si on a de l'argent que pour 25 questionnaires (sur 250 chefs de ménage)
=> le taux de sondage* est de 10%
et les quotas de :
tab. 5 - quotas par sexe
Hommes Femmes Total 12 13 25 tab. 6 - quotas par âge
18-34 35-49 50-64 65 et + Total 12 8 3 2 25 tab. 7 - quotas par CSP
Artisans Petits com. Gros com. Prof. lib. Cadres sup. Cadres moy. Employés Ouvriers Inactifs Retraités Étudiants Total 1 2 10 10 2 25 - Quotas croisés (ou indépendants)
Nécessite la connaissance de la distribution conjointe des trois variables
=> sexe * âges * CSP
- La solution est théoriquement meilleure,
mais pratiquement :
- statistiques détaillées non disponibles !!!
- contrôles trop difficiles à respecter !
- Échantillons à plusieurs degrés :
- En pratique, on procède à un sondage à deux degrés :
- tirage d'un échantillon de localités ;
puis
- tirage des individus par la méthode des quotas.
C'est la taille des localités qui donne la meilleure stratification.
- En général, on distingue :
- les communes rurales => pop. rurale agglom. au chef-lieu inférieure à 2 000 hab.
- les petites villes => [2 000 ; 10 000]
- les villes ou agglomérations moyennes => [10 000 ; 50 000]
- les grandes villes ou agglomérations => [50 000 ; 100 000]
- les très grandes agglomérations => + de 100 000 hab.
- Qu'est-ce qui a été retenu pour le RGP rénové ?
(voir la fiche mémo mem21enq.htm si trou de mémoire !)
- Le mode de désignation est le suivant :
tab. 8 - Sondage à deux degrés et désignation des quotas
Les quatre combinaisons sont possibles,
Localités Individus 1 Choix raisonné Choix raisonné 2 Tirage au sort Choix raisonné 3 Choix raisonné Tirage au sort 4 Tirage au sort Tirage au sort mais la dernière relève des tirages aléatoires !
- Inconvénient :
- repose sur le postulat suivant :
la variable étudiée repose sur la distribution des variables de contrôle !
- tributaire de la qualité des contrôles
"fraîcheur" des statistiques
- ne permet pas d'évaluer la précision des estimations
- impossibilité d'étudier les variables (fondamentales) de contrôle !
- Avantage :
- ne nécessite pas l'existence d'une base de sondage* :
- à jour ;
- sans omission ;
- sans répétition.
- économique et rapide à mettre en oeuvre (par rapport aux sondages probabilistes) ;
- adaptée aux échantillons de faible effectif ;
moins de 1 000 questionnaires (cf. ARDILLY 1994, p.156)
- adaptée aux enquêtes comportant un fort risque de refus de répondre.
L'erreur d'observation serait nettement supérieure à l'erreur aléatoire !
Pour la méthode des quotas, le principal :
- inconvénient est de laisser trop d'initiative à l'enquêteur ;
- avantage est de ne pas nécessiter de base de sondage.
La méthode des itinéraires (ou méthode Politz) essaye de combiner les deux !
- Le principe :
Méthode surtout utilisée pour tirer un échantillon de ménages ou de logements.
Elle consiste à imposer un itinéraire où sont indiqués les lieux où doivent être réalisées les interviews.
=> les conditions sont peu différentes d'un sondage aléatoire
=> chaque logement (lieu d'interview) est repéré par ses coordonnées géographiques
- Le sondage aléatoire sélectionne les individus à enquêter par tirage au hasard
=> Chaque individu a une probabilité non nulle et connue d'être choisi
- Ce mode de sondage implique 3 conditions :
- avoir la liste exhaustive de toute la population (base de sondage à jour)
- l'enquête présente un caractère obligatoire ;
- le processus de tirage est aléatoire (reproduisant le hasard).
- Le sondage aléatoire est la seule méthode fondée de façon théorique
- Avantages :
- Il fournit :
- une estimation ;
et
- une estimation de la précision de cette estimation
- La différence entre l'estimation et la réalité diminue lorsque la taille de l'échantillon augmente
- Il se prête à des traitement améliorant son efficacité :
- stratification ;
- estimateur par la régression, ...
- Inconvénient :
- Nécessite une base de sondage exhaustive* et à jour ;
- Le tirage doit être sans :
- double-compte (répétition) ;
- omission.
- Les caractéristiques de deux tirages probabilistes :
- élémentaires
- systématiques
syn. indépendants*
- Consiste à extraire au hasard dans la population mère les individus qui vont constituer l'échantillon
Le hasard, c'est différent du pifomètre !!!
Il doit y avoir équiprobabilité* des chances de tirage
- En pratique, chaque individu est numéroté
puis, il y a tirage (dés, pièces de monnaie, table de nombres aléatoires, générateur de nombres pseudo-aléatoires...)
- Doit-on remettre dans la population mère les individus tirés ?
Exemple : tirage de 10 individus sur 100
- si on remet :
- alors chaque individu a 1 chance sur 100 (proba=0,01) d'être tiré ;
- si on ne remet pas :
- alors le 1er individu a 1 chance sur 100 (proba=0,01) d'être tiré
- mais le 2ème a 1 chance sur 99 (proba=0,0101) d'être tiré
- et le 3ème a 1 chance sur 98 (proba=0,0102) d'être tiré, etc.
- L'équiprobabilité n'est plus respectée
- En pratique , les 2 méthodes sont possibles : avec ou sans remise
- avec remise
Les résultats sont identiques si M>>>>>m
- sans remise
Les résultats sont plus fidèles à la population mère si le taux de sondage est fort
Sous certaines conditions, le tirage systématique peut être considéré comme un tirage élémentaire* (syn. indépendant*).
- Il respecte l'équiprobabilité à priori des individus
tant que le tirage n'a pas commencé tous le monde à les même chances d'en être !
- Il est :
- rapide et aisé à mettre en oeuvre
- fréquemment utilisé
mais il présente un risque de biais plus élevé que le tirage élémentaire.
=> tirage d'éléments réguliers et répétitifs
- Il peut se pratiquer sur :
- une liste (noms, numéros de téléphone, d'immatriculation, ...) ;
- une grille de sondage (carte, photo...).
- Exemple
- TERUTI, Enquête du Ministère de l'agriculture qui a débuté en 1965.
A l'origine, chaque département est couvert par 1 certain nombre de photos parmi lesquelles on en tire une centaine à l'aide d'1 grille de points.
- Sur chaque partie utile de la photo (la zone centrale) une grille de 36 points est imprimée
Chaque point est :
- distant de 300 m
- visité par 1 enquêteur
- Pour la France l'échantillon fait 15 515 photographies
Pour la Seine-et-Marne, 167 photos comportant 6 012 points sont enquêtés annuellement.
- Le nombre de points "blé" est proportionnel à la surface en blé
- Le nombre de points "forêt" est proportionnel à la surface en forêt, etc.
- Cette méthode permet de constituer des sous-échantillons
Comme pour les terres labourables :
290 points sont tirés au hasard parmi les 3 350 classés en Terres Labourables en Ile-de-France
On remonte à l'agriculteur pour lui poser des questions par :
- téléphone
ou
- courrier
comme ce qu'il cultive, sa superficie, son rendement, etc.
Cela permet d'avoir une base de sondage à jour
- L'inventaire Forestier National (IFN) est un peu différent,
il comporte en plus une cartographie des formations boisées
forêt, bosquets, haies, peupleraies, landes, eau, ...
Donc, toutes les photos sont interprétées puis certains points sont enquêtés
C'est un sondage à plusieurs degrés (cf. fig.7)
- La stratification
Objectif => faire baisser l'estimation de l'imprécision (variance) des résultats
- Constitution de groupes homogènes (faible variance) ;
- Tirage d'une partie de l'échantillon dans chacun des groupes de façon indépendante ;
La variance de l'estimateur est la somme des variances des estimateurs par strate
Intuitivement on conçoit que les fluctuations dues au hasard ont été amorties.
Conclusions :
- Depuis longtemps, au moins 1953 (cf. DESABIE 1966, pp. 57-62), on a cherché à évaluer l'efficacité et les défauts des méthodes empiriques par rapport aux probabilistes. Quelques unes des conclusions sont reprises ici :
- Les tirage probabilistes nécessitent une base de sondages
Mais ils permettent de connaître :
la précision des estimations sur l'univers
- Dans le cas des quotas :
- il n'est pas nécessaire d'avoir une base de sondage à jour ;
- le résultat issu d'un petit échantillon est souvent
- aussi performant ;
- moins coûteux.
que tiré avec une méthode probabiliste
Mais on ne peut connaître le degré de fidélité de l'échantillon.
- Les procédures par stratifications ou quotas
réclament plus d'information que les tirages
- systématiques
ou
- élémentaires
Mais leurs résultats peuvent être plus fidèles à la population mère !
- Dans le cas d'une stratification améliorant un tirage probabiliste
on peut connaître le gain de précision par rapport au tirage élémentaire
|
Communiquez-moi par courrier électronique les réponses aux questions suivantes Question n°2.2.1. L'erreur aléatoire est présente dans les enquêtes par :
Question n°2.2.2. Par rapport au sondage élémentaire, le sondage en grappes permet :
Question n°2.2.3.Quelle méthode de tirage de l'échantillon permet de connaître la précision de l'estimation :
|
NB : les mots suivis de "*" font partie du vocabulaire statistique, donc leur définition doit être connue. Faites-vous un glossaire.